
NộI Dung
Nguồn: Kran77 / Dreamstime.com
Lấy đi:
Các mô hình học tập sâu đang dạy máy tính tự suy nghĩ, với một số kết quả rất thú vị và thú vị.
Học sâu đang được áp dụng cho ngày càng nhiều lĩnh vực và ngành công nghiệp. Từ những chiếc xe không người lái, đến chơi Go, để tạo ra hình ảnh âm nhạc, có những mô hình học sâu mới xuất hiện mỗi ngày. Ở đây chúng tôi đi qua một số mô hình học tập sâu phổ biến. Các nhà khoa học và nhà phát triển đang lấy những mô hình này và sửa đổi chúng theo những cách mới và sáng tạo. Chúng tôi hy vọng showcase này có thể truyền cảm hứng cho bạn để xem những gì có thể. (Để tìm hiểu về những tiến bộ trong trí tuệ nhân tạo, hãy xem Máy tính có thể bắt chước bộ não con người không?)
Phong cách thần kinh
Bạn không thể cải thiện kỹ năng lập trình của mình khi không ai quan tâm đến chất lượng phần mềm.
Người kể chuyện thần kinh

Người kể chuyện thần kinh là một mô hình mà khi được đưa ra một hình ảnh, có thể tạo ra một câu chuyện lãng mạn về hình ảnh. Đây là một món đồ chơi thú vị và bạn có thể tưởng tượng ra tương lai và xem hướng mà tất cả các mô hình trí tuệ nhân tạo này đang di chuyển.

Chức năng trên là hoạt động "thay đổi phong cách" cho phép người mẫu chuyển chú thích hình ảnh tiêu chuẩn sang phong cách truyện từ tiểu thuyết. Sự thay đổi phong cách được lấy cảm hứng từ "Thuật toán thần kinh của phong cách nghệ thuật".
Dữ liệu
Có hai nguồn dữ liệu chính được sử dụng trong mô hình này. MSCOCO là bộ dữ liệu của Microsoft chứa khoảng 300.000 hình ảnh, với mỗi hình ảnh chứa năm chú thích. MSCOCO là dữ liệu được giám sát duy nhất đang được sử dụng, có nghĩa là dữ liệu duy nhất mà con người phải truy cập và viết rõ ràng chú thích cho mỗi hình ảnh.
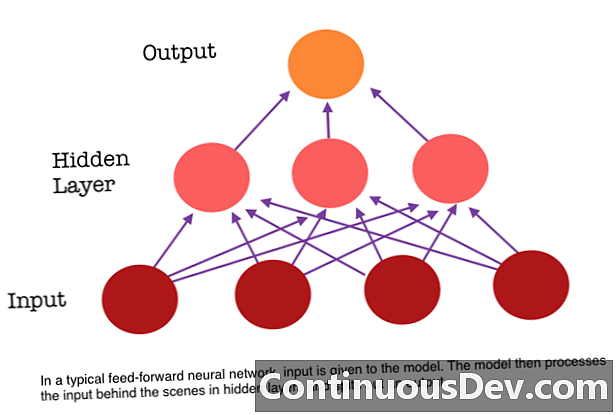
Một trong những hạn chế chính của mạng nơ ron chuyển tiếp là nó không có bộ nhớ. Mỗi dự đoán là độc lập với các tính toán trước đó, như thể đó là dự đoán đầu tiên và duy nhất mà mạng từng đưa ra. Nhưng đối với nhiều tác vụ, chẳng hạn như dịch một câu hoặc đoạn văn, các đầu vào phải bao gồm các dữ liệu liên quan và liên quan đến nhau. Ví dụ, sẽ rất khó để hiểu nghĩa của một từ trong câu nếu không có từ được cung cấp bởi các từ xung quanh.
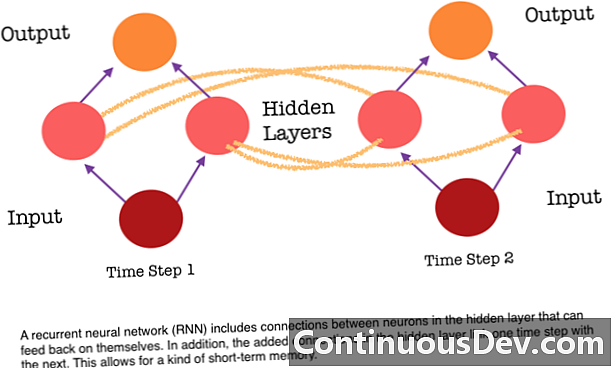
RNN khác nhau vì chúng thêm một tập hợp kết nối khác giữa các nơ-ron. Các liên kết này cho phép các kích hoạt từ các tế bào thần kinh trong một lớp ẩn để tự hồi phục vào bước tiếp theo trong chuỗi. Nói cách khác, ở mỗi bước, một lớp ẩn nhận được cả kích hoạt từ lớp bên dưới nó và cả từ bước trước đó trong chuỗi. Cấu trúc này về cơ bản cung cấp cho bộ nhớ mạng thần kinh tái phát. Vì vậy, đối với nhiệm vụ phát hiện đối tượng, RNN có thể rút ra các phân loại chó trước đây để giúp xác định xem hình ảnh hiện tại có phải là chó không.
TED-RNN
Cấu trúc linh hoạt này trong lớp ẩn cho phép RNN rất tốt cho các mô hình ngôn ngữ cấp ký tự. Char RNN, ban đầu được tạo bởi Andrej Karpathy, là một mô hình lấy một tệp làm đầu vào và huấn luyện RNN để học cách dự đoán ký tự tiếp theo theo trình tự. RNN có thể tạo ký tự theo từng ký tự sẽ trông giống như dữ liệu huấn luyện ban đầu. Một bản demo đã được đào tạo bằng cách sử dụng bảng điểm của các bài nói chuyện TED khác nhau. Cung cấp cho mô hình một hoặc một số từ khóa và nó sẽ tạo ra một đoạn về (các) từ khóa theo giọng nói / kiểu của TED Talk.
Phần kết luận
Những mô hình này cho thấy những đột phá mới trong trí thông minh máy móc đã trở nên khả thi vì học sâu. Học sâu cho thấy rằng chúng ta có thể giải quyết các vấn đề mà trước đây chúng ta không bao giờ có thể giải quyết được và chúng ta chưa đạt đến cao nguyên đó. Hy vọng sẽ thấy nhiều điều thú vị hơn như những chiếc xe không người lái trong vài năm tới là kết quả của sự đổi mới học tập sâu sắc.